Content Extraction
Content extraction is the second step in the knowledge base processing pipeline. It converts uploaded or referenced documents into a plain text or Markdown format that can be further split and embedded for AI-powered search.
You can choose between several extraction methods depending on your use case.
Markdown
This option converts the content of the document into Markdown format, preserving semantic structure like headings, bullet points, and tables.
Supported MIME Types
- Email files (
message/rfc822,application/vnd.ms-outlook) - Plain text files (
text/plain) - Markdown files (
text/markdown) - Microsoft Word documents (
application/vnd.openxmlformats-officedocument.wordprocessingml.document) - Microsoft Excel spreadsheets (
application/vnd.openxmlformats-officedocument.spreadsheetml.sheet) - Microsoft PowerPoint presentations (
application/vnd.openxmlformats-officedocument.presentationml.presentation)
Header Mapping for Microsoft Word
When extracting Microsoft Word documents, it's possible to define a header mapping to convert specific styles into Markdown-compatible headings.
This is useful when documents use custom-named heading styles (e.g., "MyTitleStyle") instead of the default "Heading 1", "Heading 2", etc.
How to identify header styles
-
Open the Styles Pane in Word and select the styled text.
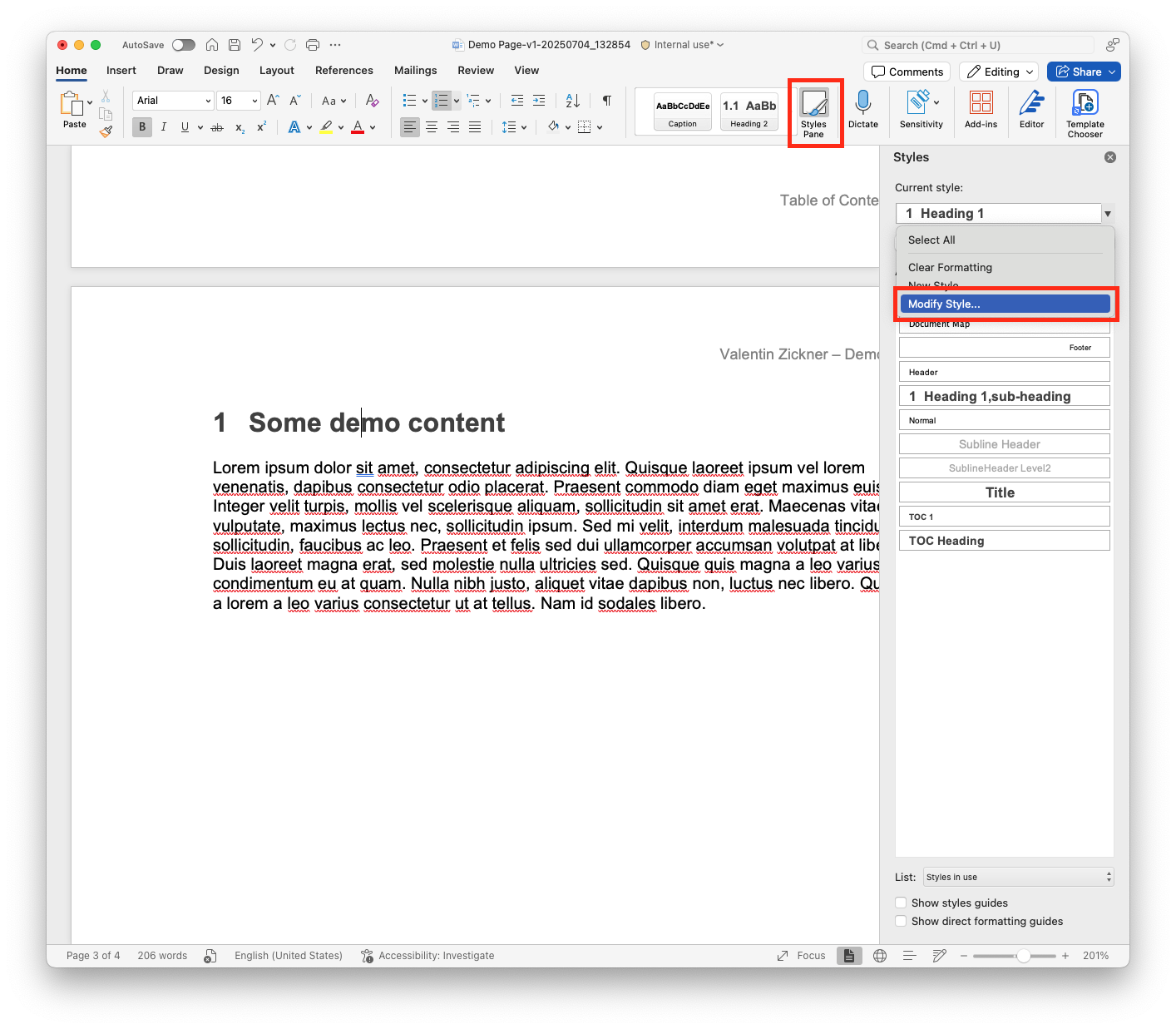
-
Click Modify Style to view the exact name of the style.
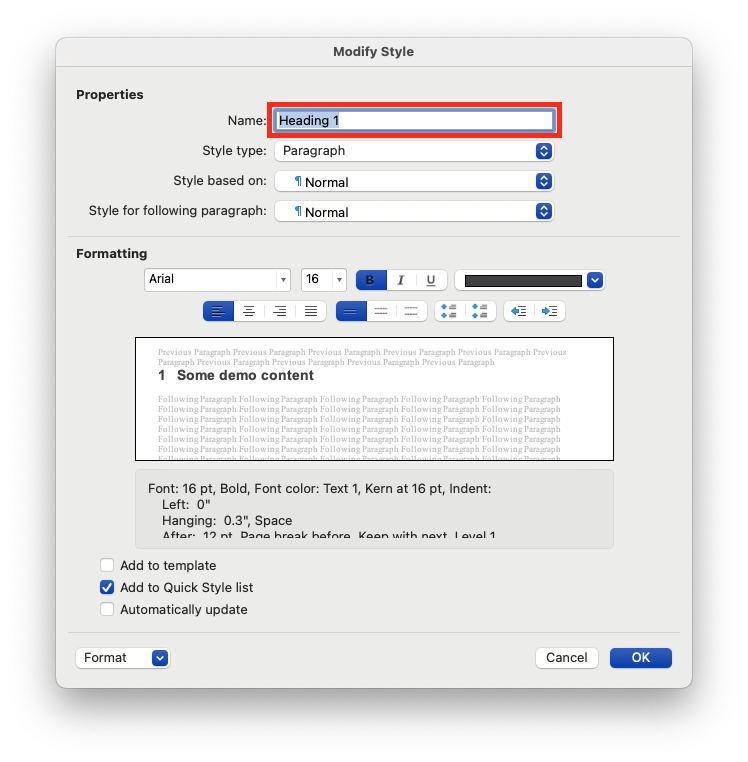
You can map multiple Word styles to the same Markdown header level.
Original Document
This option is only available when using the OpenAI Vector Store.
In this mode, the original document content is sent directly to OpenAI for parsing. Flowable does not perform any intermediate extraction or formatting.
Use this if you want OpenAI’s model to handle raw document parsing.
Custom
 warning
warningThe custom extraction APIs are currently experimental and may change in future releases.
For advanced use cases, you can implement your own extraction logic by providing a custom Java class.
Implement the following interface: com.flowable.agent.engine.impl.knowledgebase.pipeline.steps.extractor.KnowledgeBaseTextBasedFormatExtractor
This gives you full control over how content is parsed before further processing.